KT 에이블스쿨 : 5차 미니프로젝트 (1일차) - 시계열 데이터 탐색

5차 미니프로젝트
1일차 : 24.04.24 (수)
수업때 간략하게 배우고 넘어갔던 시계열 데이터를 처음 접하게됐다 .
생각대로 어려웠다.
미프 실습시간 마치고 복습하는데도 한참을 걸렸다..
3차때 미니프로젝트부터 느낀게, 코드를 함수화해서 효율성을 높이는게 중요하다고 생각들어
오늘 실습한 1일차 데이터탐색도 전부 함수화로 바꿔 복습했다.
K마트 44번 매장의 유통 판매량을 탐색한 결과를 정리할려한ㄷㅏ.
시계열 데이터 탐색
시계열 데이터 필수사항
1. 날짜를 담고있는 date 컬럼 - datetime 형으로 변환
2. 결측치 확인 - 결측치 어떻게 처리할지 ? (이동평균, 보간법 등 )
범주값 확인

매장 위치별(State, City) 매장의 개수를 확인했을때,
Minnesota(State) = 19개 / Saint Paul(City) = 18개로 전체에서 앞도적인 비중을 차지했음44번 매장 또한, Minnesota(State), Saint Paul(City)에 속해서 다른 매장과 비교를 해볼 수 있음

44번 매장은 1번에 속하는데, 매장 타입별 좋고 나쁜 정도는 데이터상 만으로는 확인 불가
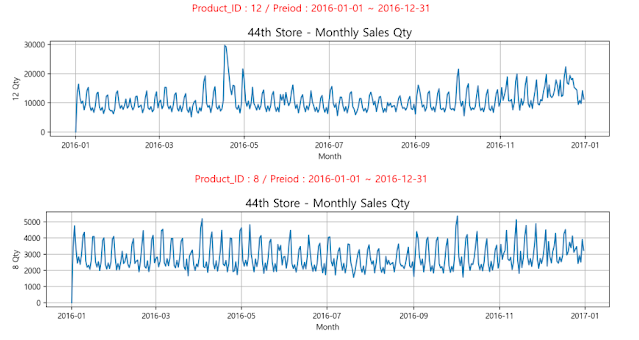
상품별 월별 판매 수량
- Total(전체 상품 판매량)과 비례해 영향을 받는건
- Product_ID = 12 인 우유 (그래프 3번째)
- Product_ID = 3인 음료 (그래프 2번째)
- Product_ID = 42인 곡물 (그래프 4번째)
- 판매량과 관련없이 연말연초에 판매량이 적고, 중순(7월 전후)로 가장 판매량이 많음
- 연초연말에는 재고를 적게, 7월에는 재고를 많이 준비하는게 좋을 듯
- 곡물 판매량은 시간(Date)와 가장 연관이 높아보임
 |
| 기간 : 3년 한줄씩, Product_ID별 데이터를 다르게 시각화한 것 |
 |
| 기간 : 1년 (2016년) 1년간 분기별 흐름을 볼 수 있음 |
월별 방문 고객수
- 방문자 수는 월별 흐름이 아주 비슷함
- 연초 (1월, 2월) 가장 판매량이 적음
- 연말에 구매를 많이해서 그런걸 수도 있고,
- 추워서 외출이 적어지는 이유도 있을듯
- 3월, 5월, 8월이 다소 판매량이 큼
- 할인이 있나 ? 공휴일이 있나 ?
- 연말(12월)에 비약적으로 판매량 증가
- 겨울 준비, 연말 파티 준비
 |
| 1번 그래프 : 기간 = 3년 2번 그래프 : 기간 = 1년 (2014년) 3번 그래프 : 기간 = 1년 (2015년) 4번 그래프 : 기간 = 1년 (2016년) |
동일 카테고리별 상품 판매량
 |
1번 그래프 : Drink (38 와인, 3 음료) 2번 그래프 : Food (12 우유, 나머지 = 프로즌, 빵, 요거트, Prepared) 3번 그래프 : Grocery (10 계란, 24 고기, 32 씨푸트, 42 곡물) |
2. 기간 : 2016년 (1년)
- Drink
- 음료(3)과 와인(38)은 연관이 없어보임
- Food
- 우유 외 나머지 food는 판매량이 적으나 요거트(8)는 개별적으로 비교해보니 동일한 추이를 보임
- Grocery
- 곡물(42)과 계란(10)이 판매량이 대부분을 차지함
- 계란을 사는 추이와 비슷해보여 추가 분석을 해보니, 달라보임

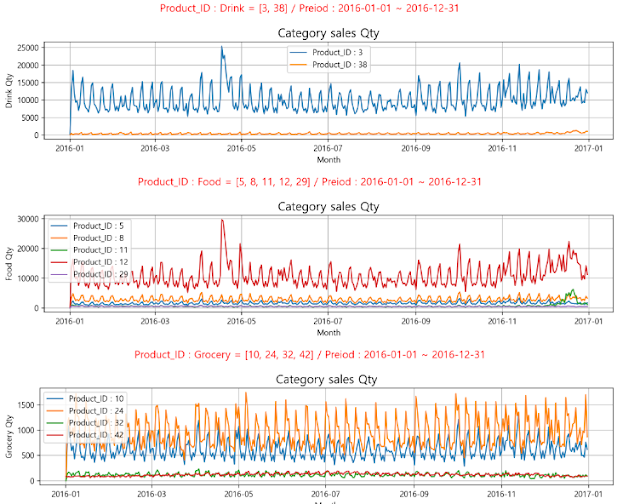 |
| 2016년(1년간) 카테고리별 상품 판매량 - 시각화 |
휘발유
휘발유 가격과 상품 판매량 비교

2주간 휘발유 가격 평균(MA)과 상품 판매량 비교
oil = oil_price.loc[oil_price['Date'].between(start, end)]
oil['WTI_Price'] = oil['WTI_Price'].rolling(14, min_periods=1).mean()
다변량 비교
방문 고객수와 상품 판매량 비교
- 방문자가 많을 수록 우유(12)는 거의 동일하게 움직임
- 방문자가 기본 생필품으로 우유를 사서 일듯
- 음료(3)는 연관이 있는듯 없는 듯 잘모르겠음
- 다만, 연말마다 음료의 판매량이 비약적으로 증가함
- 곡식(42)은 방문자와 비례하지 않음
- 방문자는 연말마다 증가하지만, 곡식은 연초연말에 가장 판매량이 적음
같은 지역 매장과 방문 고객수 비교
44번 매장과 같은 City (Saint Paul), State (Minnesota)에 있는 매장을 비교하면 좋을 것 같아 추가분석을 해봤다.
- 같은 city, 같은 state, 같은 store_type(1)
- 매우 동일한 추이를 가짐

- 같은 city, 같은 state, 다른 store_type(2)
- Store_ID = 9인 매장은 2017년 데이터가 삭제된 걸로 보임
- Store_ID = 20 인 경우, Date가 2015-02-13일 부터 시작함
(다른건 2014-01-02부터 시작)

- 같은 city, 같은 state, 다른 store_type(3)
- 비슷해 보임

- 같은 city, 같은 state, 다른 store_type(4)
- 특히 Store_ID = 1, 2 인 경우는 추이가 많이 다름

Diff 변화량 비교
상품별 변화 비교
- 변화량: tmp['Qtydiff'] = tmp['Qty'].diff()
- 전체 상품
- 감소할땐 최대 -30,000 ~ 증가할땐 +20,000
- 연말연초에 비약적으로 증가하니, 전체저으로 재고 비축 필요
- 음료(3) 상품
- 감소할땐 최대 -10,000 ~ 증가할땐 +5,000
- 우유(12) 상품
- 변화량의 분포가 아주 이쁜 정규분포 형태
- 감소, 증대가 크지 않음
- 곡식(42) 상품
- 왼쪽으로 꼬리가 김

요일별 변화 비교
- 변화량 : tmp['Qtydiff'] = tmp['Qty'].diff()
- 요일별 : tmp['Weekday'] = tmp['Date'].dt.weekday
- 상품의 구분 없이 요일별 비슷한 변화가 있음
- 월요일에 판매량이 가장 적음
- 수요일 또한 판매량이 적음 (일주일 중 두번째로 판매량이 적은 날)
- 토요일에 판매량이 가장 많음
- 금요일 또한 판매량이 많음 (일주일 중 두번째로 판매량이 많은 날)

시계열 분해
상품별 변화 비교
2016년 (1년간)

2015년 (1년간)

2014년 (1년간)

개선할 점
merge의 실패
5개 데이터프레임(sales, orders, oil_price, stores, products) 의 상관계수를 확인하기 위해서
하나의 df으로 합쳤는데, 나중에 보니 완전 잘못된 merge였다.
total = pd.merge(sales, orders, on=['Date', 'Store_ID'], how='left')
total = pd.merge(total, oil_price, on='Date', how='inner')
total = pd.merge(total, stores, on='Store_ID', how='inner')
total = pd.merge(total, products, on='Product_ID', how='inner')
sns.heatmap(total.corr(numeric_only = True), annot=True, fmt='.3f', cbar=False, cmap='Blues')
plt.show()
 |
| 잘못된 merge 데이터프레임의 상관계수 히트맵 (내일 제대로 merge하고 난 뒤의 상관계수랑 확인하면 좋을듯) |
이렇게 left, inner 조인으로 df을 모두 merge했는데,
데이터프레임별 1:n / 1:1 형태를 고려하지 않고 그냥 바로 합쳐서
이후에 데이터탐색을 할때 아래같은 요상한 시각화가 나왔음

sales 데이터프레임은 Date : Product_ID = n : 1
orders 데이터프레임은 Date : CustomerCount = 1 : 1 인데 sales의 date을 기준으로 merge한게 가장 큰 문제였다.

sales의 date를 기준으로 merge하니까, 같은날짜의 Product_ID 별로 매장방문자수(CustomerCount)가 각각 들어가니까, 전체 방문자수가 n번 곱해지는 이상한 데이터가 됨
⇒ sales의 일일 전체 판매량 Qty로 groupby하고, customercount랑 합쳐야함 (df1 -- daily_sales_total)
일일 1행이 나오기위해서는, product_ID와 같이 제품별 정보에 대한건 삭제가 필요할 듯
⇒ 그래야, 일일 전체 판매량 - 전체 방문자수를 나타내는 1일 1행이 나옴
- 일일별 어떤 상품이 팔렸는지 확인하기 위해서는 하루별 상품 데이터프레임이 필요함 (df2 -- daily_product)
함수화
3차 분류, 회귀 프로젝트를 하면서부터 파이프라인, 함수화하기 시작했다.
여전히 함수화하는게 익숙하지 않아서, 실행셀마다 코드를 작성했는데, 비효율적인걸 오늘 제대로 느꼈다.
기업에서 데이터분석을 처리하고, 프로그램을 만들어 서비스화 시켰을때
함수로 만들어야 더 효율적으로 처리를 할수가 있고, 다른사람들도 쉽게 사용이 가능해지기 때문에 함수화하는거에 익숙해져야한다고 생가
추가 분석하고 싶은거


댓글
댓글 쓰기